
– data analysis is easy but insight is paramount for actionable reporting: getting the right data is just as important as getting the data right.
Database administration — from architecture to deployment — is always easier said than done because it requires multi-dimensional professionals empowered by unique intersections of skill-sets in order to interpolate reality into business-logic for data-processing; databases are just as easily taken for granted by even the most seasoned of software engineers but they are always immensely appreciated upon deployment.
Our graduate-research at GWMSIST began with creating a database mission-statement, which was a completely foreign-concept until we learned just how key it can be for data-integrity:
Our mission is to satisfy our customer’s rental-car needs while delivering the best quality, service and value; we believe the ideal system is a human-centered user-experience modeled according to a consistent object-oriented model from the front-end of the application to the back-end of the database. Concordantly, we believe both the entity relationship diagram and relational database-model specifications required by the rental-car management inventory system will seek to:
- Proactively maintain and monitor the database system to prevent any potential issues.
- Accurately diagnose and forecast the database system health and capacity to maximize return on investment for the rental-car inventory management system and promptly respond to the stakeholder’s support request(s) to remove any work bottleneck on DBA side.
- Persistently seek innovative ways to improve DBA work efficiently yet effectively.
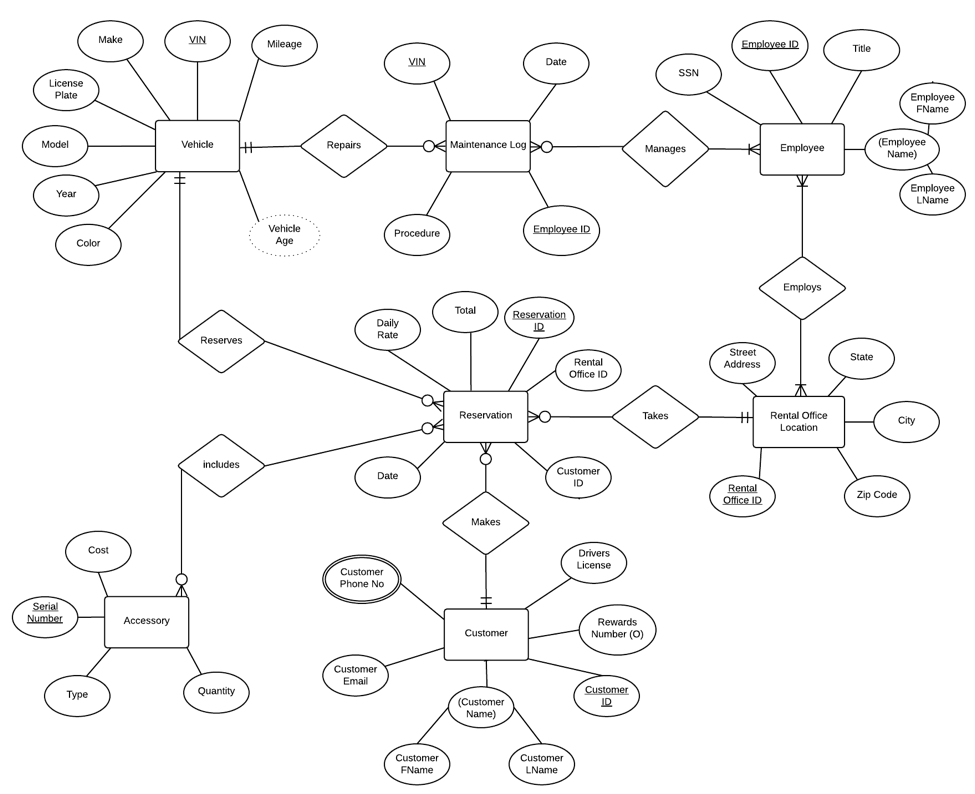
Database Entity Relationship Diagram
Project kick-off began with identifying and cataloguing all of the entities defined by specific attributes for a rental-car inventory system and how they are related to other entities and attributes within the database system visualized as an Entity-Relationship Diagram (ERD) to organize degrees of relationships by cardinality, which by definition is the number of occurrences in one entity that are associated (or linked) to the number of occurrences ordered by optionality provided thusly:
- One-to-One
- One-to-Many
- Many-to-Many
It is important to note these distinctions as they essentially determine how data is relatable to other data within the system because all of the data must be connected for eventual retrieval. In the ERD below, A Vehicle entity may be optionally related to a Reservation; conversely, a Reservation must be related to one Vehicle. Ternary relationships occur when three entities participate in a defined relationship- for example, the Vehicle and Reservation entity-tables are related by the Reserves entity-table; this dynamic is more clearly defined in the next section explaining database-modeling.
Database Modeling
Upon completion of the ERD, database architecture is ready for modeling, ideally in a guided-user interface structured-query language (SQL) developer client like Oracle SQL Developer or MySQL Workbench, which enables database-administrators to transcribe an ERD into a database-model for transfer of entities and attributes into database-tables and data-types, respectively, where each data-type essentially becomes a column to contain rows of records for that database table-entity; for example, note the Vehicle database-table entity in the below diagram: this table can organize a vehicle’s data visualized as one row, just as if it were to be viewed within an Excel spreadsheet.
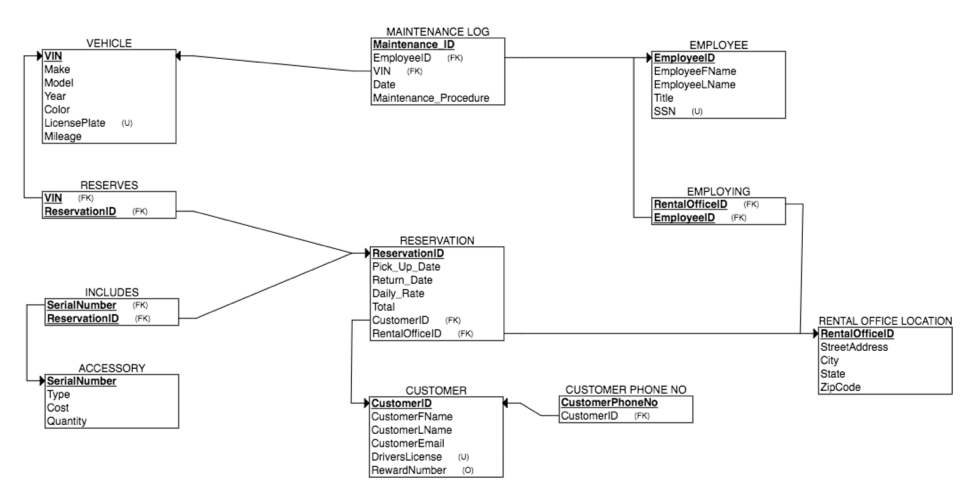
Each table is generally catalogued by a unique identifier called a primary-key; however, a table may contain other foreign-keys to other relationships within that model.
Database Administration
Upon transcribing the database-model derived from the ERD presumably treated with data-type declarations, a SQL-developer application-client can generate the script necessary to create the database-structure- in this case, the create.sql file from this GitHub repo presented in the below Gist.
Also note the insert.sql script contained within the GitHub repo inserting data into the database: each insert statement “seeds” the data according to the data-types specified for their corresponding entity-attributes structured in the database. Observe the Pick_Up_Date and Return_Date attributes within the Reservation-table: these attributes were assigned with the SQL data-type DATE, which in this case are not “NULL-able” meaning that instance-field requires a specific data-type (e.g.”March 03, 2017″ input as 20170301) and cannot contain an “empty-set,” or blank field for that row, as a table-entry, exhibited within the Gist below from the repository available for review at GitHub.
After generating scripts derived from the database-model and seeding the database on a local-environment, the database is ready for deployment on a hosting-provider like Amazon Web Services Relational Database Service (AWS RDS), a robust solution to set up, operate, and scale a relational database for cloud-computing.
Deploying to Amazon Web Services
Our research required a deployable instance for server-side integration. Although databases are maintained, operated and connected via localhost to the same virtual-machine hosting an application, databases can be remotely connected to another computer on a different network for risk-mitigation and redundancy.
The AWS RDS offerings range from micro instances with 1 GiB RAM for experimental prototypes to 244 GiB RAM for massive builds; a tutorial is provided above to demonstrate how to launch an Amazon Web Services Relational Database Service via MariaDB.
Structured Queried Language
The Google Slides-deck above for our GWMSIST database research presents the Top-5 queries selected from our executable, report.sql– note the corresponding terminal-output for a given query; data analysis is easy but insight is paramount for actionable reporting: getting the right data is just as important as getting the data-right. There is big-league demand for Data-Wranglers because they are multi-dimensional professionals empowered by unique intersections of skill-sets- from programming with Python and SQL to reporting involving calculus and inferential-statistics.

SQL is a programming language used to query, or retrieve data from a database- to not only create databases, but add, modify and delete database structures or insert, delete and modify existing records. In spite of new paradigms like non-relational database management systems (NoSQL) emerging on the digital frontier, SQL will endure for the foreseeable future of relational database management systems (RDMS)– the foundation of contemporary database management system software packages that are used to implement the majority of today’s operational databases and analytical databases; the former stores information required for application processing, while the latter archives data from the operational database to offload processing for analytics and reporting. Our entire SQL-report executable is presented in the below Gist, including pseudo-code comments to describe the desired terminal-output.
Post Mortem
Any-time a user populates a form, and that data is exchanged locally or on the web, that data is being stored on a database for eventual recall and retrieval. Database design and administration is an iterative process like all information systems engineering- from prototyping to deployment, there are continuous integrations and modifications in Agile development; our research and development evolved with every pull-request until we were ready to ship. Upon examining the salient points from our research post-mortem, like “all the things in tech,” there is always so much more than meets the eye, and thus appreciate (our research is accessible in entirety via scribd– also below the next section).
- Our initial models included two relations that had identical names: “Reserves.” This was a simple oversight that merely required us to alter the name of the relation between Accessory and Reservation to “Includes.”
- Our initial design called for a ternary relationship between Vehicle, Accessory, and Reservation tables. However, after discussion we decided to divide the single relation out into two separate relations, one between Vehicle and Reservation tables, and one between Accessory and Reservation tables. Our logic behind this decision is that it is fully possible for a reservation to not have any accessories attached to it, and by automatically including a column for the accessory serial number in the relation table could result in a significant amount of null values for that column, which would have served as a foreign key. In dividing the two relations into separate tables, we were able to ensure that there would be no null foreign key values.
- The initial design only allowed for a single phone number to be assigned to each customer. However, after discussion it was decided that this would not be sufficient, as multiple contact numbers are common. To solve for this, we added an additional table that is linked to the Customer table, using CustomerID as a foreign key to incorporate multiple phone numbers. Our initial implementation of this table was incorrect though, as there was no primary key assigned to the table. After testing the initial table CREATE and data INSERT statements, we discovered our error and established the phone number column as the primary key column.
- At the start, we had misstated the requirements necessary for how tracking vehicle maintenance would work. We had incorrectly assumed a one to many relationship between the vehicle and the employee, thus overlooking the need for a relational table that linked these two entities. Once the requirements had been corrected, we also designed the Maintenance_Log table, that would store the necessary, and relevant data, for tracking maintenance updates performed on the vehicles in question.
- Our updated design called for a column labelled “Procedure” in the Maintenance_Log Table. During our design phase though, we did not realize that “Procedure” is a reserved term in SQL, and it would not be possible for us to use this title for the column. After troubleshooting our CREATE statement, we discovered the error, and had to backtrack and update our design to re-name this column “Maintenance_Procedure.”
- Our updated design was also lacking another critical piece of data in regards to the Maintenance_Log table: the primary key. After experiencing some issues in creating and populating the table, we realized that each individual procedure would needs its own unique identifier, and added in the Maintenance_ID column.
- In defining the requirements for our Reservation table, we had specified the need to store data that would allow for the calculation of total cost of the reservation, and decided to do so by tracking the dates of the rental and the daily cost. However, in our initial design, the table only had a single column for reservation dates. Storing this data in a single column would not have allowed us to easily track the total number of days that the reservation spanned, so we had to update the database to hold an additional column, thus allowing us to split the dates into a Pick_Up_Date column and a Return_date column.
GWMSIST Rental Car Inventory Relational Database System Research by Alex Singleton on Scribd